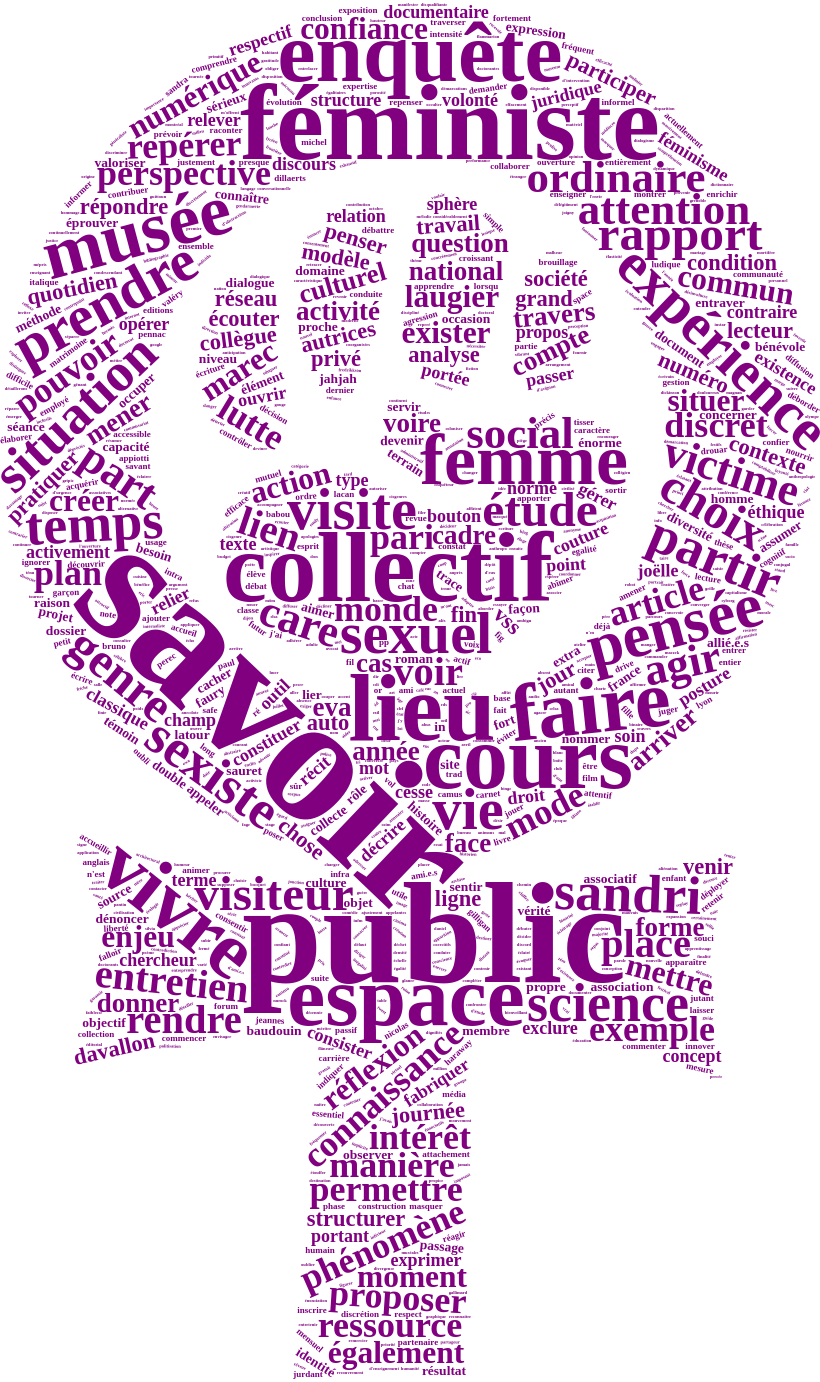
|
Wordcloud pour illustrer un articleLibrairies library(tidyverse) library(tidytext) library(pdftools) library(proustr) library(stopwords) library("mixr") # Lise Vaudor package library(magick) library(wordcloud2) Récupérer le texte du PDF Avec la fonction pdf_text du package pdf_tools txt <- pdf_text("Article Revue Balisages_Joëlle Le Marec et Eva Sandri_25 octobre 2022.pdf") On obtient ainsi un chr de 17 éléments (correspondants aux 17 pages) Une question se pose, qu’est ce que je garde, pourquoi, comment ? Est ce que j’enlève titre et abstract ? noms d’autrice, biblio ? |
tidytext

|
La Gazette, mon petit canard : ConcoursConcours de la Gazette de Montpellier Le jeu-concours : racontez-nous, sur le thème “La Gazette, mon petit canard”, une histoire ou anecdote que vous inspire La Gazette : texte (court), poème, chanson, vidéo, rap, histoire drôle, tableau, sculpture… Laissez parler votre créativité. Les créations les plus originales, amusantes, pertinentes, émouvantes, acides, délirantes,… gagneront l’un des 35 lots. Surprenez-nous ! Envoyez votre production (texte, vidéo, photo, etc.) par mail à jb. |

|
Analysis of Umbrella Academy's scripts - Part 1The bible of text mining with R (by Julia Silge and David Robinson) is very, very helpful ! I would like to see the evolution of the characters through the episodes but the scripts that I found no permit to do this because they don’t precise who is speaking 😞. Well, you have the scripts in a data frame, but not very tidy. library(tidyverse) library(tidytext) Words frequency df <- readRDS("df.RDS") %>% mutate(episode_number = str_extract(episodes_titles, "\\d*"), # extract 1 chiffre ou plus episode_title = str_extract(episodes_titles, "(? |
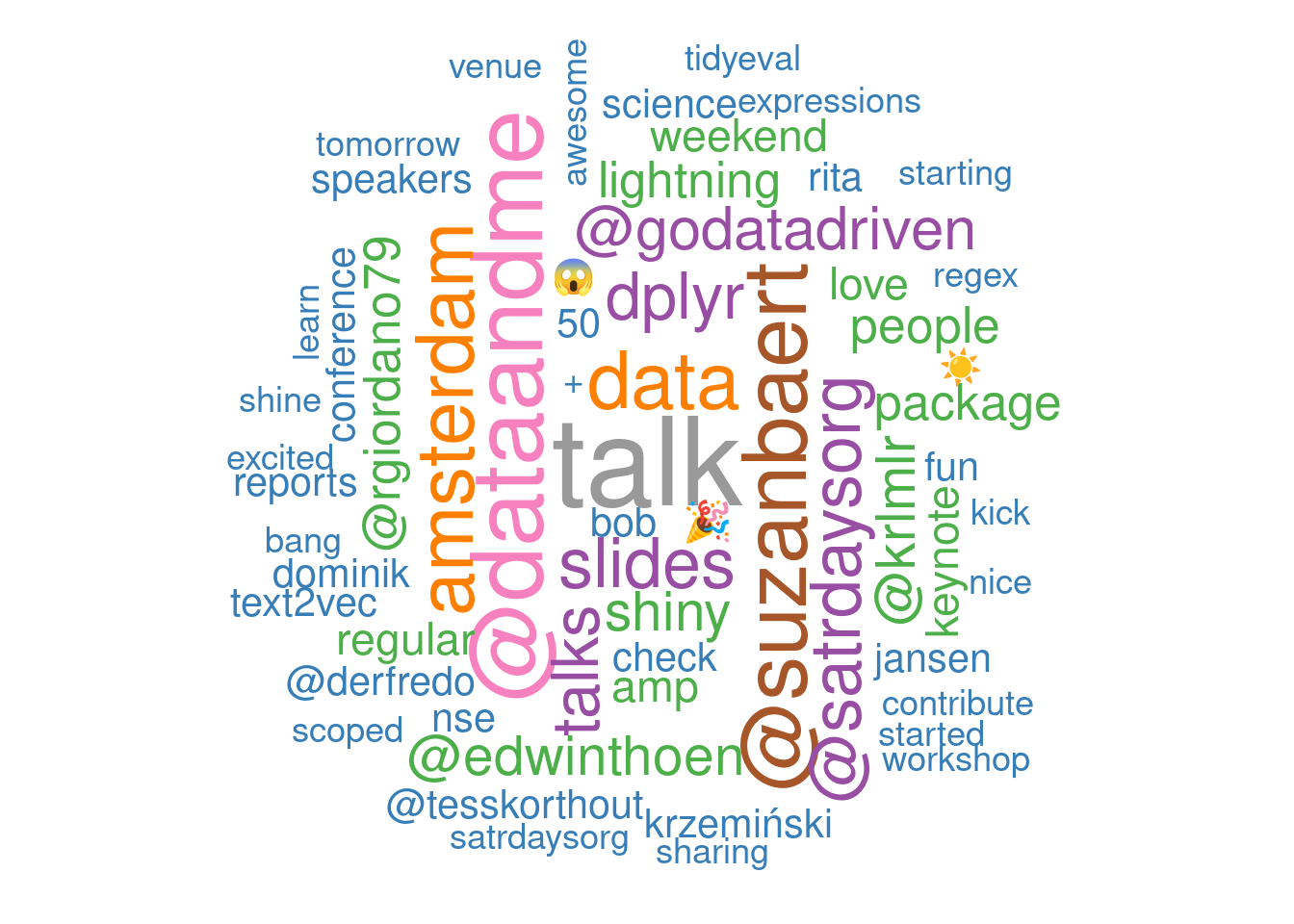
|
AmstRday's tweetsThese lines of code have been lying around in a file for more than 2 months. I wrote them after SatRdays Amsterdam in September. Packages installation library(tidyverse) library(rtweet) library(knitr) library(kableExtra) library(ggiraph) library(magick) library(tidytext) library(wordcloud) library(widyr) library(igraph) library(ggraph) library(ggmap) library(maps) library(plotly) Scraping the tweets # rt_AmsteRday <- search_tweets( # "#AmsteRday", n = 2, include_rts = FALSE # ) # rt <- rt_AmsteRday # # vect <- c("#AmstRday", "#satRday", "#satRdays", "#satRdayAMS", "#satRdaysAMS") # # for( vec in vect){ # # rt_vec <- search_tweets( # vec, n = 18000, include_rts = FALSE # ) # rt <- bind_rows(rt, rt_vec) # } # # # rt <- rt %>% # unique() # # saveRDS(rt, "conttweets. |